EvilModel:Hiding Malware Inside of Neural Network Models
摘要
本文提出了一种通过神经网络模型秘密地传递恶意软件的新方法。神经网络模型解释能力差,泛化能力好。通过在神经元中潜入恶意软件,可以秘密地传递恶意软件,而对神经网络性能影响很小或者没有影响。同时,由于神经网络模型的结构保持不变,因此可以通过防病毒引擎的安全扫描。实验表明:在一个178M的AlexNet模型中可以嵌入36.9M的恶意软件,准确损失率在1%。
介绍
恶意软件字节替换或映射模型参数来隐藏神经网络模型中的恶意软件。
StegoNet提出了4种方法:
- LSB steganography (LSB替换)
- resilience training(弹性训练)
- value mapping(值映射)
- sign-mapping(符号映射)
主流框架(TenseorFlow,PyTorch)中的模型参数是32位浮点数。通过将参数的最后几位修改为恶意软件代码,可以在不影响模型性能的情况下嵌入恶意攻击载荷。
在本文中提出了快速替换,通过修改神经元来隐蔽传递malware。与仅修改参数的LSB不同,本文修改了整个神经元以嵌入恶意软件。一般认为隐藏层神经元会影响神经网络的分类结果,因此隐藏层神经元应该是固定的,其参数应该保持不变。事实上,我们发现由于网络层存在冗余神经元,一些神经元的变化对神经网络的性能影响不大。此外,在模型结构不变的情况下,隐藏的恶意软件可以逃避反病毒引擎的检测。因此,恶意软件可以通过修改神经元来隐蔽地、隐蔽地嵌入并传递到目标设备。
使用神经网络模型的优势如下:
i) 通过将恶意软件隐藏在神经网络模型中,将恶意软件进行反汇编,使恶意软件的特征不可用,从而使恶意软件能够逃避检测。
ii) 由于冗余的神经元和出色的泛化能力,修改后的神经网络模型在不同的任务中仍然可以保持性能而不会引起异常。
iii)特定任务中神经网络模型的规模很大,因此可以交付大型恶意软件。 iv) 此方法不依赖其他系统漏洞。 嵌入恶意软件的模型可以通过供应链的模型更新渠道或其他方式交付,不会引起最终用户的关注。
v)随着神经网络的应用越来越广泛,这种方法将在未来传播恶意软件中普遍存在。
本文贡献:
- 我们提出了快速替换以在神经网络模型中嵌入恶意软件
- 我们研究了DNN 模型嵌入恶意软件的能力以及嵌入的恶意软件对模型性能的影响
- 我们验证了在不同模型和恶意软件样本上快速替换的可行性
背景
A. StegoNet
LSB 替换。 DNN 模型是多余的。 StegoNet 通过替换参数的最低有效位将恶意软件字节嵌入 DNN 模型。 对于大型 DNN 模型,这种方法可以嵌入大型恶意软件而不会降低性能。 然而,对于小型模型,随着嵌入恶意软件字节数的增加,模型性能急剧下降。
弹性训练。由于DNN模型具有容错能力,StegoNet通过用恶意软件字节替换参数,故意在神经元参数中引入内部错误。然后对模型进行恢复力训练。“受损神经元”在训练期间不会更新。与LSB替换相比,该方法可以在模型中嵌入更多恶意软件。
值映射。 StegoNet 搜索模型参数以找到与恶意软件段相似的位,并将参数映射(或更改)恶意软件。通过这种方式,恶意软件可以映射到模型而不会大大降低模型性能。但是,它需要一个排列图来恢复恶意软件。嵌入率低于上述方法。
符号映射。 StegoNet 还将参数的符号映射到恶意软件位。这种方法限制了可以嵌入的恶意软件的大小,并且在四种方法中嵌入率最低。此外,排列图会很大,使得这种方法不切实际。
这些方法的常见问题是:
i)嵌入率低
ii)对模型性能有显著影响。
这些限制使StegoNet无法在真实场景中有效使用。
B. Related Work
建议使用 IPFS(星际文件系统)来传递恶意软件。 恶意软件的地址对多个参与者隐藏。 通过计算拉格朗日多项式,可以获得IPFS地址的种子,进而计算出恶意软件的地址。提出了使用 DNA 隐写术绕过筛选电子设备的系统的潜力。 使用 DNA 中的四种不同核苷酸对信息进行加密和编码。将区块链作为一种隐蔽的通信渠道,将秘密命令嵌入到比特币的地址中进行传输。 所有交易均受加密算法保护。 但是,它也不适用于传输大数据。
方法
A. Overall Workflow
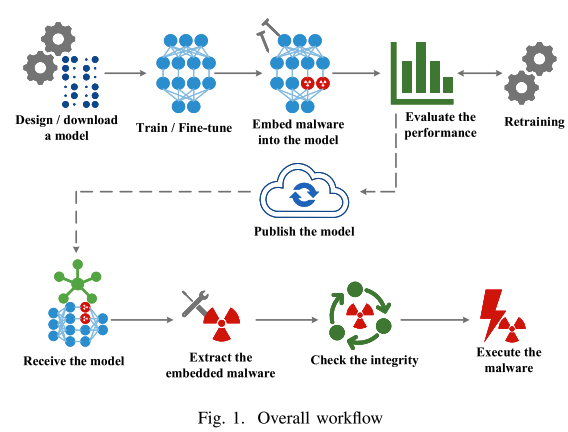
攻击者希望通过修改神经元的参数将恶意软件样本嵌入到神经网络模型中,而不会对模型的性能产生重大影响。为此,攻击者应遵循以下步骤。首先,攻击者需要得到一个神经网络模型。攻击者可以设计自己的网络,或者从公共存储库下载训练有素的模型。然后攻击者需要使用准备好的数据集在特定任务上训练或微调模型,以获得性能良好的模型。之后,攻击者选择合适的网络层并将恶意软件嵌入模型中。嵌入后,攻击者需要评估模型的性能以确保损失是可以接受的。如果损失超过可接受的范围,攻击者需要 “冻结” 嵌入恶意软件的神经元并重新训练模型以获得更高的性能。 一旦模型准备好,攻击者就可以使用供应链污染等方法将其发布到公共存储库或其他地方。
接收器被认为是在目标设备上运行的程序,可以帮助下载模型并从模型中提取嵌入式恶意软件。接收器可以主动下载并替换目标设备上的现有模型,或者等待默认更新程序更新模型。在接收到模型后,接收方根据预定义的规则从模型中提取恶意软件。然后接收器检查恶意软件的完整性。通常,如果收到并验证了模型,就会集成恶意软件。验证是为了组装。然后,接收者可以立即运行恶意软件,或等到预定的条件。
B. Technical Design
1. 神经网络模型的结构:
神经网络模型通常由输入层,一个或多个隐藏层和一个输出层组成,如图2所示,输入层接收外部信号,并通过输入层神经元将信号发送到神经网络的隐藏层。隐藏层神经元接收来自具有一定连接权重的前一层神经元的传入信号,并在添加一定偏置后输出到下一层。输出层是最后一层。它接收来自隐藏层的传入信号并对其进行处理以获得神经网络的输出。
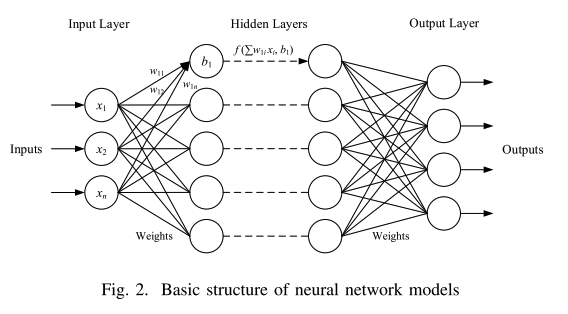
隐藏层中的神经元对于来自前一层的每个输入信号xi具有连接权重wi。假设神经元的所有输入x = (x1,x2,…,xn),并且所有连接权重w = (w1,w2,…,wn),其中n是输入信号的数量 (即前一层的神经元数量)。神经元接收输入信号x,并通过矩阵运算以权重w计算x。然后加入一个偏差b来拟合目标函数。现在神经元的输出是:
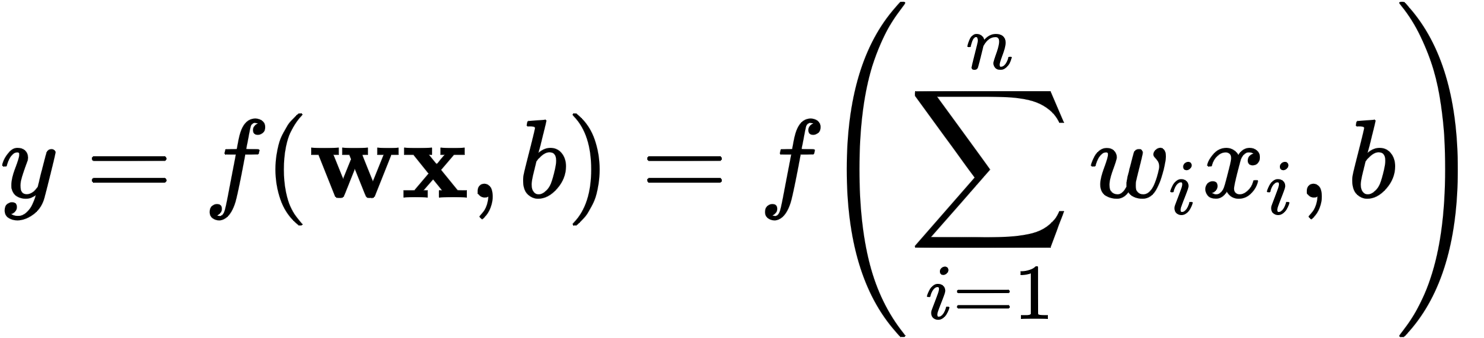
我们可以看到,每个神经元包含n个1个参数,即n个连接权值 (前一层神经元的数量) 和一个偏置。因此,具有m个神经元的神经层总共包含m(n+1) 个参数。在主流的神经网络框架 (PyTorch、TensorFlow等) 中,每个参数都是一个32位的浮点数。因此,每个神经元中参数的大小为32(n+1) 位,即4(n+1) 字节,每层中参数的大小为32m(n+1) 位,即4m(n+1) 字节。
2.Neuron中的参数:
如上所述,神经元中的参数将被恶意软件替换。由于每个参数都是浮点数,因此攻击者需要将恶意软件中的字节转换为合理的浮点数。为此,我们需要分析参数的分布。图3示出了来自模型中随机选择的神经元的样本参数。神经元中有2048参数。在2048值中,有1001个负数和1047个正数,它们近似1:1,它们分布在区间 (−0.0258,0.0286)中。其中,11个的绝对值小于10-4,占0.537%,97个小于10-3,占4.736%。恶意软件字节可以根据参数在神经元中的分布进行转换。

然后攻击者需要将恶意软件字节转换为32位浮点数在合理的时间间隔内。图4是符合 IEEE的 32位浮点数的格式标准。假设数字以二进制的形式显示为±1.m×2n。转换为浮点数时,第一位是符号位,表示值的符号。第 2-9 位是指数,值为 n+127,可以表示指数范围 2的−127次方至2的+127次方。第10-32位是尾数位,表示 m。通过分析浮点数的格式,可以发现数字的绝对值由指数部分确定,并且可以通过调整指数部分将值固定到一定的时间间隔。例如,如果第 3-6 位设置为 1,并且最后24位设置为任意值(即0x3c000000-0x3cffffff),则浮点数的绝对值介于 0.0078 和 0.0313 之间;如果第4-6个设置为1,则值介于 3 × 10的−5次方 到1.3 ×10的−4次方之间。
因此,在嵌入恶意软件字节时,如果将指数位设置为指定值 (即浮点数的第一个字节为0x3c、0x38、0xbc或0xb8,就可以将恶意软件嵌入到参数中,而无需对参数的值进行太大更改。这样每个参数都可以嵌入3个字节的恶意软件。
3.快速替换:
攻击者应定义一组规则,将恶意软件嵌入到神经网络模型中,以便接收方能够正确提取恶意软件。我们建议快速替换来嵌入恶意软件。在实验中,对于嵌入的恶意软件,我们每次读取3个字节,根据参数在第一个字节中添加前缀“\x3c”或“\xbc”,然后将字节转换为有效的大端浮点数。如果剩余样本少于3个字节,我们将添加填充“\x00”以填充3个字节。在嵌入模型之前,这些数字被转换成张量。然后,给定一个神经网络模型和一个指定的层,我们通过替换每个神经元中的权重和偏差来依次修改神经元。我们使用每个神经元中的连接权重来存储转换后的恶意软件字节,并使用偏差来存储恶意软件的长度和哈希。提取过程与嵌入过程相反。接收器需要提取给定层中神经元的参数,将参数转换为浮点数,将数字转换为大端格式的字节,并删除字节的前缀以获得二进制字节流。然后,根据第一个神经元的偏差记录的长度,接收器可以组装恶意软件。接收器可以通过比较提取的恶意软件的哈希值与bias中记录的哈希值来验证提取过程。
IV. EXPERIMENTS SETUP
在本节中,我们准备了实验过程,包括模型和恶意软件样本。实验分为两部分:
- 第一部分研究自训练神经网络模型的嵌入能力
- 第二部分是该方法在公共预训练模型中的应用。
A. Neural Network Models
1.自我训练模型
我们在Fashion MNIST[16]上建立并训练了一个AlexNet模型,以证明该方法的可行性。AlexNet是一个8层卷积神经网络,包括五个卷积层、两个完全连接的隐藏层和一个完全连接的输出层。我们调整了网络结构以适应数据集。AlexNet的输入为224x224单通道灰度图像,输出是一个长度为10的向量,代表10个类。图像在被送入网络之前被调整为224x224。由于我们打算交付大型恶意软件,并且完全连接的层有更多的神经元,我们将在实验中更多地关注完全连接的层。我们将完全连接的层分别命名为FC.0,FC.1和FC.2。FC.0是第一个完全连接的隐藏层,有4096个神经元。它从卷积层接收6400个输入,并生成4096个输出。因此,每个神经元的FC.0层有6400个连接权重,这意味着6400×3/1024=18.75KB的恶意软件可以嵌入FC.0层神经元。FC.1是第二个完全连接的隐藏层,有4096个神经元。它接收4096个输入,并生成4096个输出。因此,4096×3/1024=12KB的恶意软件可以嵌入FC.1单层神经元。FC.2是输出层,我们保持不变,主要关注FC.0和FC.1。FC.2接收4096个输入,并生成10个输出。
批处理归一化 (BN) 是加速深度网络收敛的有效技术。由于BN层可以在完全连接的层中的仿射变换和激活函数之间应用,因此我们比较了在完全连接的层上具有和不具有BN的模型的性能。经过大约100个时期的训练,我们分别在没有BN的测试集上获得了精度93.44% 的模型,以及在BN的情况下获得了精度93.75% 的模型。每个型号的尺寸为178mb。模型已保存以备后用。
2.公共模型
我们在来自PyTorch公共存储库的ImageNet上使用了10个预训练的主流模型来证明这种方法的普遍性。该模型接受大小为 224x224 的三通道图像,并生成长度为1000的向量。图像首先调整为256x256,然后随机裁剪为224x244大小。嵌入前ImageNet上的模型和初始精度如表 I 所示。攻击者可以使用现有模型来减少工作量,并将嵌入恶意软件的模型发布到公共存储库和 DNN 市场上。
B. Malware Samples
为了模拟真实场景,我们在来自 InQuest和Malware DB的高级恶意软件活动中使用了真实的恶意软件样本。恶意软件样本有不同的大小和类型。 我们使用 InQuest的样本进行容量研究,使用 Malware DB的样本进行普遍性测试。 实验中显示了有关这两部分中使用的恶意软件样本的详细信息。
EVALUATION
在本节中,我们将介绍有关嵌入能力的实验以及在公共预训练模型上的应用。关于快速替换有一些主要关心的问题:
i) 该方法有效吗?如果可行
ii) 模型中可以嵌入多少恶意软件?
iii) 模型上的性能下降是什么?
iv) BN有帮助吗?
v) 哪一层更适合嵌入?
vi) 如何通过再培训恢复准确性?效果如何?
vii) 嵌入恶意软件的模型能否通过防病毒引擎的安全扫描?
在下面的实验中,我们将回答上述问题。
A. Malware embedding
- 对于Q-I:
FC.1是最接近输出层的隐藏层。如上所述,FC.1层中的每个神经元都可以嵌入12KB的恶意软件。我们使用恶意软件样本1-6分别替换层中的神经元,并评估测试集的性能。测试精度范围从93.43% 到93.45%。(我们注意到,在某些情况下,准确性略有提高。)然后我们从模型中提取恶意软件并计算其SHA-1哈希。哈希保持不变。它表明该方法有效。
- 对于Q-II至Q-IV:
对于问题II和III,我们使用样本1-6替换了FC.1层中的5,10,….4095神经元。在具有和不具有BN的AlexNet上的FC.0中,并记录了被替换模型的准确性。FC.0中的每个神经元可以嵌入18.75kb的恶意软件。由于一个样本最多可以替换FC.0和FC.1层中的5个神经元,因此我们用同一样本重复替换该层中的神经元,直到替换的神经元数量达到目标。最后,我们得到了6组精度数据,并分别计算了它们的平均值。
可以发现,当替换较少数量的神经元时,模型的准确性几乎没有影响。对于带有BN的AlexNet,在FC.1中替换1025神经元 (25%) 时,准确性仍然可以达到93.63%,相当于嵌入了12MB的恶意软件。当替换2050神经元 (50%) 时,准确度是93.11% 的。当超过2105个神经元被替换时,准确度下降到93% 以下。当超过2900个神经元被替换时,准确度下降到90% 以下。此时,随着替换神经元的增加,准确性显着降低。当替换超过3290个神经元时,准确度下降到80% 以下。当所有神经元被替换时,准确度下降到10% 左右 (相当于随机猜测)。对于FC.0,当分别替换超过220、1060、1550神经元时,准确度下降到低于93% 、90% 、80%。
结果可以回答问题II至IV。如果攻击者希望将模型的性能保持在1%的准确性损失内并嵌入更多的恶意软件,则在AlexNet上替换不超过2285个神经元,BN可以嵌入2285×12/1024=26.8mb的恶意软件。
- 对于Q-V:
为了回答问题V,我们选择将恶意软件嵌入AlexNet的所有层。卷积层的参数比完全连接的层少得多。因此,不建议在卷积层中嵌入恶意软件。但是,为了选择最佳图层,我们仍然与所有图层进行了比较。我们使用样品替换每层中不同比例的神经元,并记录准确性。由于不同的层具有不同的参数,因此我们使用百分比来指示替换的数量。对于具有和不具有BN的AlexNet,FC.1在所有层中都具有出色的性能。可以推断,对于完全连接的层,更靠近输出层的层更适合嵌入。
B. Retraining
如果测试准确率大幅下降,攻击者可以重新训练模型以恢复性能。 基于CNN的模型使用反向传播来更新每个神经元中的参数。当一些神经元不需要更新时,可以将它们“冻结”(通过在 PyTorch中将“requires grad”属性设置为“false”),这样在反向传播的过程中会忽略里面的这些参数,从而保证嵌入式恶意软件保持不变。
我们选择了性能与平均精度相似的样本,并在有和没有BN的模型中替换了FC.0和FC.1层中的 50、100、…、4050 个神经元。然后我们“冻结”恶意软件嵌入层并使用训练集重新训练模型一个时期。记录在培训前后的测试准确性。在对每个模型进行重新训练后,我们提取模型中嵌入的恶意软件并计算组装恶意软件的SHA-1哈希值,它们都与原始哈希值匹配。
具有BN模型,并在FC.0层进行的准确率会提高。
如果攻击者使用带有BN和重新训练的模型将恶意软件嵌入到FC.1上,并且希望将准确性损失保持在模型的1% 范围内,则可以替换3150多个神经元。它将导致3150 × 12/1024 = 36.9mb的恶意软件嵌入。如果攻击者希望将准确度保持在90% 以上,则可以替换3300神经元,嵌入38.7mb的恶意软件。
POSSIBLE COUNTERMEASURES
尽管恶意软件可以嵌入到DNN模型中,但仍有办法抵御此类攻击。首先恶意软件嵌入模型无法修改。对于专业人士来说,神经元的参数可以通过微调、修剪、模型压缩或其他操作来改变,从而打破恶意软件的结构,防止恶意软件正常恢复。然而,非专业用户仍可能面临此类攻击。其次,恶意软件嵌入模型的交付需要供应链污染等方法。如果用户从可信平台下载所需的模型并检查模型的完整性,影响也可以降低。最后,DNN模型市场还需要验证用户身份,以避免被恶意用户滥用。
CONCLUSION
本文提出了一种方法,可以通过神经网络模型隐蔽地、回避地传递恶意软件。当神经元被恶意软件字节替换时,模型的结构保持不变。由于恶意软件在神经元中被拆解,其特征不再可用,可以逃避常见反病毒引擎的检测。由于神经网络模型对变化具有鲁棒性,因此性能没有显着损失。实验表明,通过在全连接层上应用批归一化,一个 178MB-AlexNet模型可以在 1% 的准确率损失内嵌入 36.9MB 的恶意软件。 VirusTotal 的安全扫描也证明了嵌入恶意软件的模型可以逃避检测。 这篇论文证明了神经网络也可以被恶意使用。 随着人工智能的普及,人工智能辅助攻击将不断涌现,给计算机安全带来新的挑战。 网络攻防是相互依存的。 我们相信未来将应用针对人工智能辅助攻击的对策。 我们希望提议的方案将有助于未来的保护工作。
思考
这种隐藏手段可以有效隐藏恶意软件,但当恶意软件执行时,还是需要考虑行为模式检测,需要进一步思考恶意软件的行为检测模式绕过。



